Automatisation
- Détection de données sensibles grâce à l’IA et un ensemble de règles
- Plusieurs fonctions d’anonymisation prédéfinies
- Création d’un jeu de données en un clic
- Restauration d’un jeu de données en un clic


Jusqu’à 60% de productivité en plus des équipes de test
+ de 12 fonctions prédéfinies d’anonymisation
0 Lignes de code nécessaires pour l'automatisation
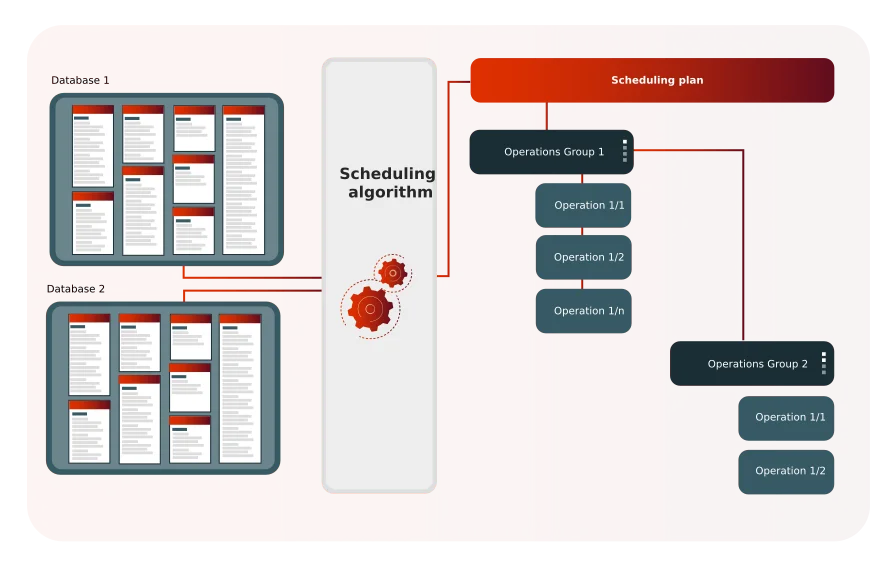
Grapes propose un algorithme innovant pour gérer efficacement les opérations d'export/import de données, même dans les bases de données les plus complexes. Cet algorithme garantit une exécution rapide des tâches, respectant les contraintes d'intégrité. Accessible à tous les utilisateurs, il simplifie la gestion des données sans nécessiter une expertise approfondie en bases de données ou en modélisation.
Quel que soit votre profil : développeur, testeur, chef de projet, créer un
environnement de test est un se fait en un clic deux mouvements avec Grapes. A
partir d’un jeu de données sauvegarder, sélectionnez l’environnement cible et sur
simple clic, les données sont restaurées sur votre environnement.
Aucune information technique, aucun mot de passe n’est demandé. Tout est déjà
pré-renseigné par votre administrateur de bases de données.

Grâce à notre IA et à un ensemble de règles intelligentes, toutes les données
sensibles sont détectées automatiquement. Grapes détecte plus de 10 types de données
à caractère personnel ou sensible.
Grâce aux fonctions d’anonymisation intégrées vous pouvez facilement masquer et/ou
anonymiser ces données.

Avec Grapes vous pouvez figer vos jeux de données et les stocker afin de les réutiliser dans le cadre de vos tests fonctionnels ou de non-régression.

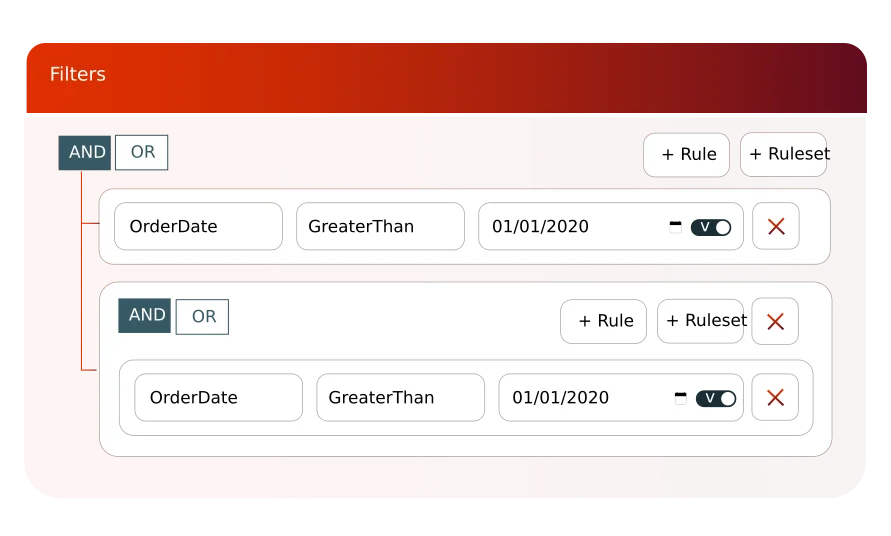
Grâce aux fonctions de filtrage vous pouvez sélectionner vos jeux de données sur la base de vos recherches. Aucune connaissance technique n’est nécessaire.
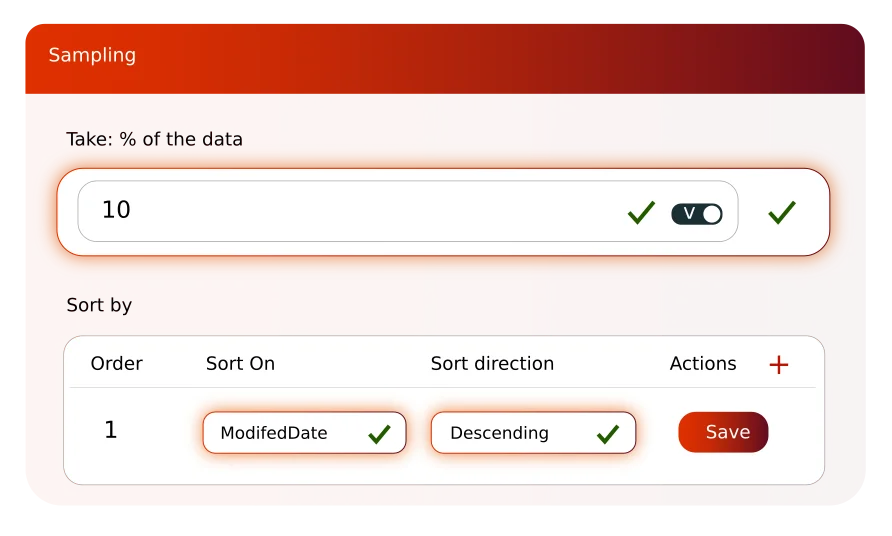
Grâce à la fonctionnalité d’échantillonnage vous pouvez sélectionner un échantillon représentatif de vos données de production sans pour autant stocker l’ensemble de données dans vos bases de données de test.

2 mai 2024
L’automatisation des données de test est devenue une pièce maîtresse dans le puzzle complexe du développement logiciel moderne. Mais qu’est-ce que c’est vraiment et comment cela peut-il bénéficier à votre entreprise ? Qu’est-ce que l’automatisation des données de test? Imaginez-vous en train de construire une maison. Avant de poser la première pierre, vous voulez vous assurer que chaque composant, chaque pièce s'emboîte parfaitement, sans faille. C'est exactement là que l'automatisation des données de test entre en jeu dans le monde du développement logiciel.
Voir plus20 mai 2024
Avec l’avènement des réglementations telles que le RGPD, la confidentialité des données est devenue une priorité absolue pour les entreprises. Dans cet article, Nous allons répondre à certaines des questions les plus courantes auxquelles nos clients sont confrontés aujourd’hui. Quel est le rôle de l’anonymisation dans le respect du RGPD ? Dans un monde où les données sont de plus en plus partagées entre différents environnements, de la production aux tests, l’anonymisation devient essentielle.
Voir plus14 juin 2023
Dans le paysage numérique actuel, la gestion efficace des données de test est cruciale pour le développement logiciel et la garantie de la qualité des produits. Cependant, avec la multitude d’outils disponibles sur le marché, il peut être difficile de déterminer quelle solution convient le mieux à vos besoins spécifiques. Examinons et comparons ensemble les différentes solutions et outils de données de test, en mettant particulièrement l’accent sur les solutions ETL (Extract, Transform, Load) et TDM (Test Data Management).
Voir plus14 juin 2023
Les tests de logiciels sont cruciaux pour garantir la qualité et la fiabilité des produits informatiques. Cependant, même les équipes de test les plus expérimentées peuvent parfois commettre des erreurs qui compromettent l’efficacité de leurs processus. Voici trois des erreurs les plus courantes à éviter : Réutiliser les Mêmes Données de Test L’une des erreurs les plus fréquentes dans les équipes de test est la réutilisation excessive des mêmes ensembles de données pour différents scénarios de test.
Voir plus